In the Age of AI, Translation Memory Still Holds Its Ground
Translation memory (TM) is the cornerstone of every localization program. It will continue to play an important role in the age of AI, too. This article briefly defines what it is and illustrates how it works.
What Is It?
Think of a TM file as a bilingual database. It stores, tracks, and maintains translations from one language to another (or many others).
It's like an Excel spreadsheet. In Column A, the sentences comprising your source-language documentation – or strings comprising your web app, etc. – are broken down into individual units and stored in individual cells. In Column B, translations are entered in corresponding cells.
A translation tool–eg, Phrase, MemoQ, XTM, Lokalise, Transifex, etc.–needs to be running with translation memory enabled. The tool will pair the source and target units together into what is called a 'segment.'
When just getting started on a project without any TM data to leverage, the editing environment in which a translator works would generally look like this. TM matches display a 0% match across the board because the TM is empty.

The translator then adds translations, segment by segment. Each one is saved into a database on the back end of the translation tool in use.
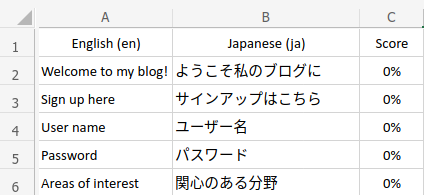
After saving to the translation memory, Segments 2 - 6 are available to be individually or collectively recalled any time the translation tool detects the same or similar source strings. That's when the '0%' scores in Column C will start to change.
Let me demonstrate. Let's say a month goes by and a minor update is made to one of the strings in this example: the word 'here' is replaced with the word 'today' in Segment 3. The rest of the segments are identical to the first time around. The translation tool will apply the TM to the strings and show one of five results:
- In-context exact (ICE) matches or 101% matches
- 100% matches
- Fuzzy matches (matches between 1% - 99%)
- New words (0% matches)
- Repetitions (or repeated words or external matches)
(There are other nuanced categories of translation memory matching that I will cover in a separate article.)
The translator will log in and see this. Her work will be only one-tenth of the volume she translated the first time around. The price will also be significantly less, which is crucially important for buyers of translation services to understand.

101%??
A score of 101% means an in-context exact (ICE) match. It means that not only has the segment been translated before, word-for-word, but that the segment above and below it have as well. You should not have to pay anything for 101% matches.
Questions You Should Ask
If you are new to the world of translation and looking to engage the services of a language service provider (LSP) for the first time, some important questions to ask about TM:
- Is the TM your intellectual property?
- Is it portable? I.e., can the TMS / LSP export the translation memory file into a common format and share it with you? The most commons ones are:• TMX• XLIFF• CSV• XLSX• XLS
- If so, will the TM contain all metadata? Your TMS should make it clear in their help documentation, like Crowdin does (see screenshot below).
- Does the LSP charge for managing it? If so, ask them to explain how and why they do so. (It can be a good idea having a localization engineer maintain it.)
Pricing Impact
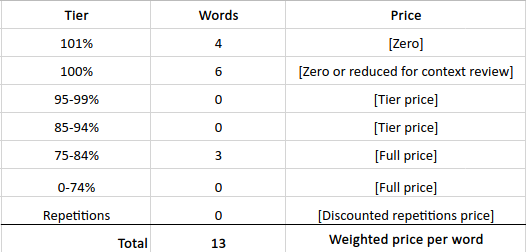
LSPs invoice based on word counts. The first invoice would be based on 13 new words. 'New words' means there was no translation memory data available for recycling exact or similar work done in the past.
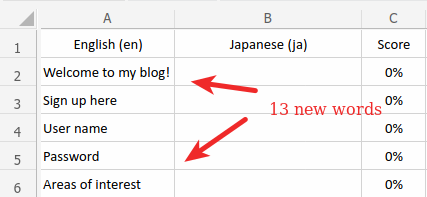
The situation was much different in the second round, where only one word changed. Two segments scored a 101% match, another two scored 100%, and one scored 75%. Your LSP will send you a breakdown of these tiers with the number of words in each tier. The ultimate result will be a weighted price per word that over time will save you a great deal of money.
I provide concrete examples about cost savings using a TM in the post Part 3: Pricing and Leverage.
Meantime, please contact me if you have any questions. Happy to help.